

Table of Links
3 SUTRA Approach
4 Training Multilingual Tokenizers
5 Multilingual MMLU
5.1 Massive Multitask Language Understanding
5.2 Extending MMLU to Multiple Languages and 5.3 Consistent Performance across Languages
5.4 Comparing with leading models for Multilingual Performance
6 Quantitative Evaluation for Real-Time Queries
7 Discussion and Conclusion, and References
3.3 Training Data
The key to our language training strategy lies in leveraging linguistic commonalities during the language learning phase. For example, Hindi has a lot more commonalities in terms of semantics, grammar and cultural context with Gujarati or Bengali as compared to Nordic languages.
The limited multilingual capabilities of large language models (LLMs) stem from an uneven data distribution favoring a handful of well-resourced languages. Multilingual data in machine translation is task-specific and misses key training areas for LLMs, such as conversation, summarization, and instruction-following. To address this, the SUTRA dataset includes over 100 million conversations in real and synthetically translated pairs across various languages, supplemented by publicly available datasets for a comprehensive training landscape. Past research has demonstrated synthetic data’s role in fostering reasoning, code generation, and task complexity learning in LLMs, as well as enhancing cross-lingual transfer with multilingual synthetic data [Lai et al., 2023, Whitehouse et al., 2023]. Following this insight, we adopt a methodical use of abundant data from languages like English to facilitate concept learning. During the language learning and alignment phases of multilingual training, we employ a combination of real and synthetic data to bolster
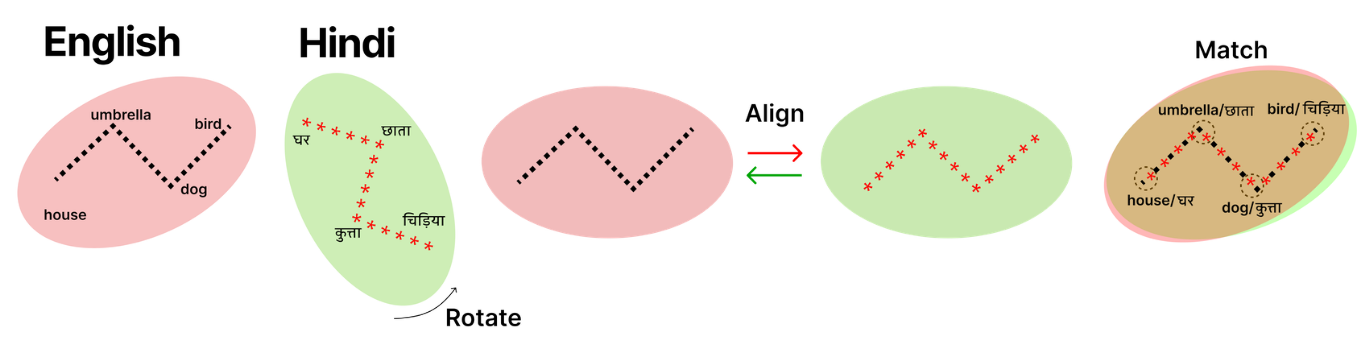
and broaden our training framework. An illustration and description of the matching and alignment process is shown in Figure 3.
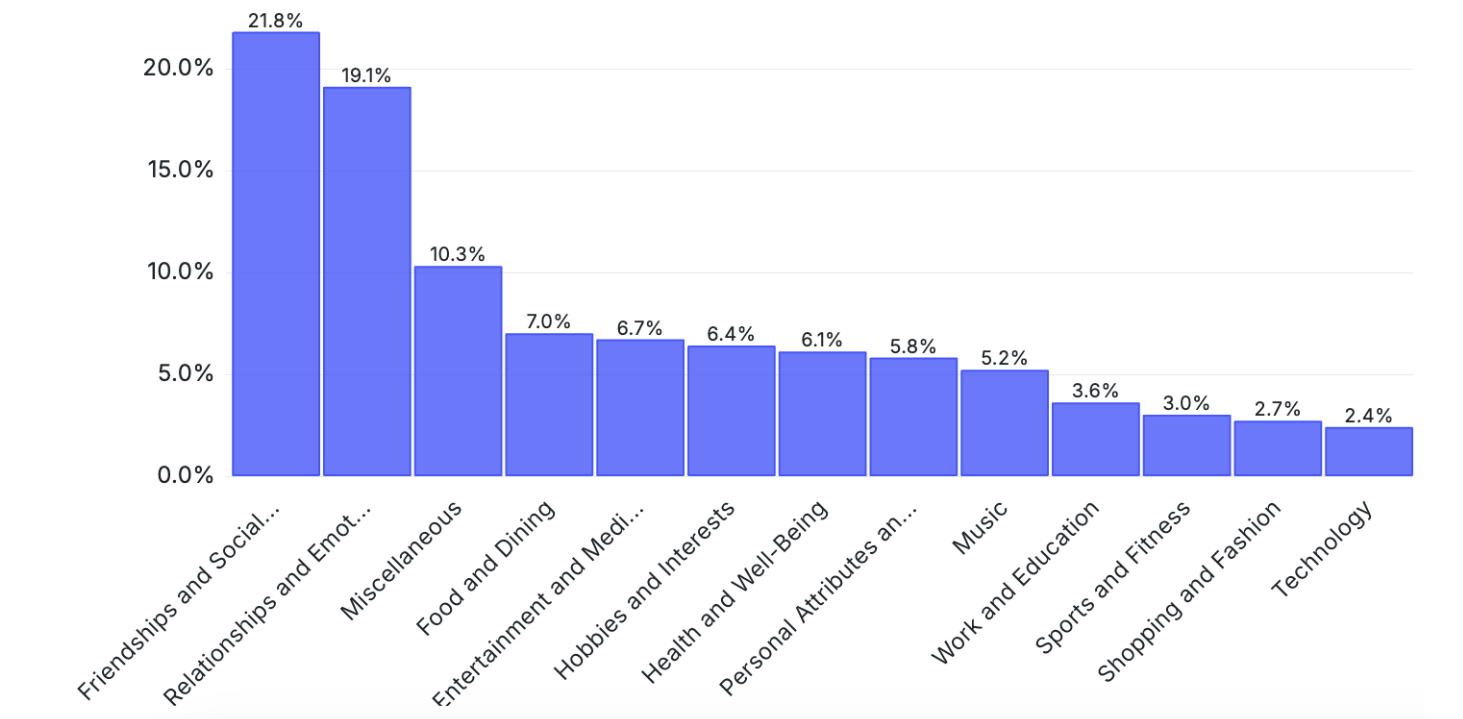
In Figure 4 we show the topic distribution of over 1M sampled conversations. Inspection of cluster centroids reveals that this is a rich and diverse data covering a wide range of topics.
The purpose-built multi-language tokenizers efficiently represent each language. They are trained on cross-lingual data and finely tuned with the base model, setting a new benchmark in multilingual language modeling. One of the most critical aspects of having good performance of conversational LLMs is high-quality instruction fine-tuning (IFT) datasets. Majority of IFT datasets are in English. We use Neutral Machine Translation (NMT) to translate the
![Table 3: In this table, statistics of various leading conversation datasets are shown such as Anthropic HH [Bai et al., 2022], OpenAssistant Conversations [Köpf et al., 2023], LMSys [Chiang et al., 2024] and the SUTRA dataset. The tokens are counted using Llama2 tokenizer [Touvron et al., 2023] for public datasets and for SUTRA dataset using SUTRA’s tokenizer. One of the key aspects of our dataset is having long term and multi-turn conversations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-mba34q4.png)
instructions, inputs and outputs from different datasets, to ensure balanced representation across tasks, in multiple Indian and non-English languages. Overall, we prepare more than 100M training samples from languages like English, Hindi, Tamil, Korean etc. with wide ranging datasets such as our internal SUTRA dataset, as well as open-source FLAN-v2, OpenAssistant and wikiHow. The translated examples are filtered to retain high-quality examples. Note that our internal data includes long-term and multi-turn conversational data, which helps to tune it towards better human-AI conversations and interactions. A comparison and detailed description of the dataset is shown in Table 3.
Authors:
(1) Abhijit Bendale, Two Platforms ([email protected]);
(2) Michael Sapienza, Two Platforms ([email protected]);
(3) Steven Ripplinger, Two Platforms ([email protected]);
(4) Simon Gibbs, Two Platforms ([email protected]);
(5) Jaewon Lee, Two Platforms ([email protected]);
(6) Pranav Mistry, Two Platforms ([email protected]).
This paper is