

Table of Links
3 SUTRA Approach
4 Training Multilingual Tokenizers
5 Multilingual MMLU
5.1 Massive Multitask Language Understanding
5.2 Extending MMLU to Multiple Languages and 5.3 Consistent Performance across Languages
5.4 Comparing with leading models for Multilingual Performance
6 Quantitative Evaluation for Real-Time Queries
7 Discussion and Conclusion, and References
3.2 Architecture
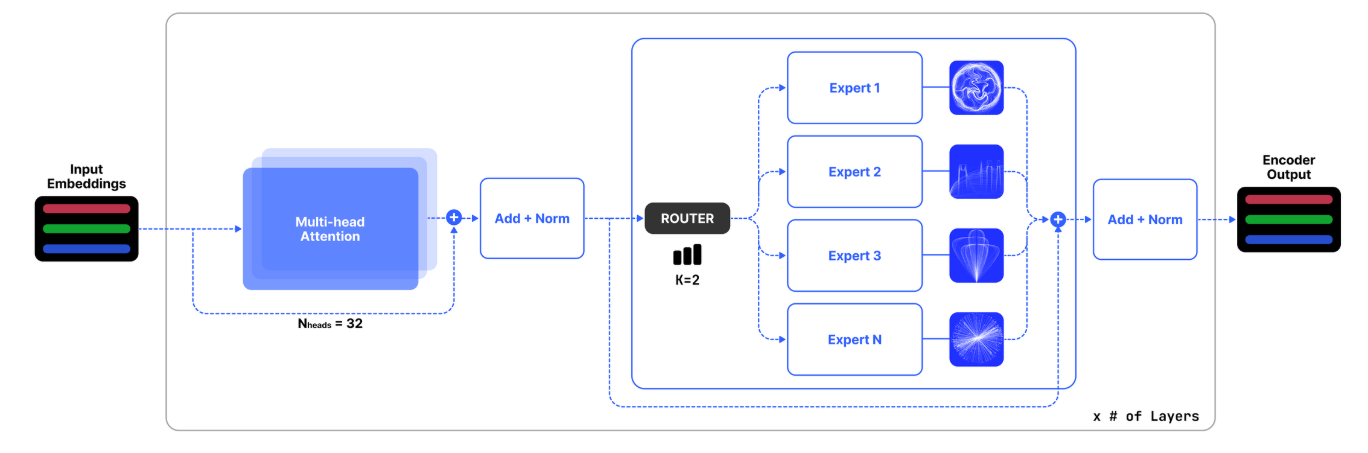
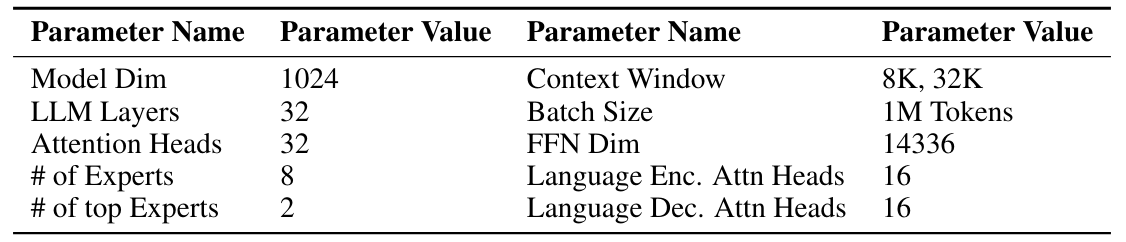
The architecture of our model, referred to herein as SUTRA, is built upon the foundational principles of the transformer architecture as delineated by Vaswani et al. [2017]. Our model retains the enhancements specified by Jiang et al. [2023], with the critical adaptation that it facilitates an extended dense context length of up to 32k tokens. Moreover, we have employed MoE layers, enabling selective activation of experts and leading to efficiency in computation and memory consumption, as shown in Figure 2. The key architectural parameters of SUTRA are encapsulated in Table 2.
Given an input x, the output yielded by the Expert Mixture module is the sum of each expert network’s contribution, modulated by the gating network. Formally, for n experts {E0, E1, ..., En−1}, the resultant output is:

where G(x)i represents the gating function’s output, producing an n-dimensional vector corresponding to the i-th expert’s activation, while Ei(x) delineates the i-th expert network’s output. The model capitalizes on sparsity by disregarding inactive experts, thereby conserving computational resources. Several mechanisms for constructing the gating function G(x) exist [Clark et al., 2022, Hazimeh et al., 2021, Zhou et al., 2022]; however, our implementation opts for the efficient approach of selecting the Top-K values from a linear projection, followed by a softmax operation [Shazeer et al., 2017]:

Authors:
(1) Abhijit Bendale, Two Platforms ([email protected]);
(2) Michael Sapienza, Two Platforms ([email protected]);
(3) Steven Ripplinger, Two Platforms ([email protected]);
(4) Simon Gibbs, Two Platforms ([email protected]);
(5) Jaewon Lee, Two Platforms ([email protected]);
(6) Pranav Mistry, Two Platforms ([email protected]).
This paper is