

Table of Links
3 SUTRA Approach
4 Training Multilingual Tokenizers
5 Multilingual MMLU
5.1 Massive Multitask Language Understanding
5.2 Extending MMLU to Multiple Languages and 5.3 Consistent Performance across Languages
5.4 Comparing with leading models for Multilingual Performance
6 Quantitative Evaluation for Real-Time Queries
7 Discussion and Conclusion, and References
5.4 Comparing with leading models for Multilingual Performance
For our evaluation, we use multiple state of the art models and compare their performance on the multilingual MMLU benchmark, as shown in Table 6. We considered multiple leading models such as GPT-4 and GPT-3.5 from OpenAI,
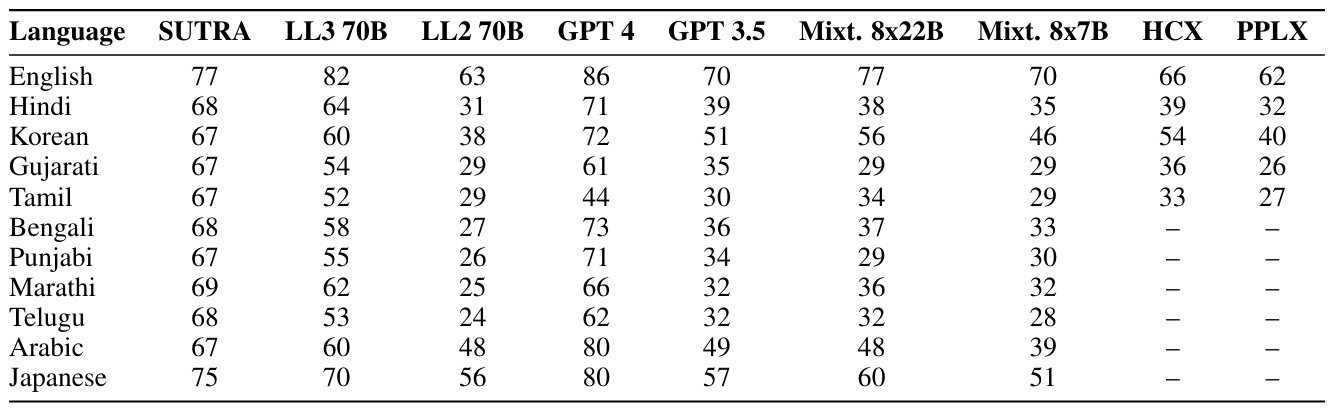
Mixtral-8x7b from Mistral, Llama2-13b, Llama2-70b and Llama3-70b from Meta, sonar-medium from Perplexity, HyperClovaX from Naver, and Airavata Model from Sarvam AI. Of these, GPT-4, GPT-3.5, Mixtral, Llama series and Perplexity are generic models i.e. they were not trained to optimize for specific languages. HyperClovaX was specifically trained to optimize performance on the Korean language, whilst Airavata was specifically trained to optimize performance in Hindi.
Overall, the evaluation results demonstrate that our SUTRA models can match and even outperform GPT-3.5 and Llama-7b on TWO-related use cases, particularly for providing natural and engaging responses across languages. Although GPT-4 is still state-of-the-art in terms of performance, cost continues to be a major hindrance for wide-scale deployment in cost-sensitive markets. Surpassing GPT-3.5 multilingual performance by 20-30% on the leading MMLU benchmark, SUTRA models excel in comprehending and generating responses across numerous languages. We find that SUTRA does well even compared to models that were specifically optimized for a particular language, showing promise for the approach followed by SUTRA, as shown in Table 7. More detailed results showing MMLU scores across groups of categories such as STEM, humanities etc. are listed in Table 8.
![Table 7: The above table shows comparison of language specific LLMs for multiple languages such as Hindi [Gala et al., 2024], Korean [Son et al., 2024], Arabic [Sengupta et al., 2023] and Japanese [Group et al., 2024]. The selected models are best performing models on respective languages, as they were purposely built and tuned for those languages. Shown on the right is MMLU score for SUTRA on respective languages. From the performance numbers it is evident that the concept and language modeling approach followed by SUTRA yields superior multilingual performance.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-sc934ba.png)
Authors:
(1) Abhijit Bendale, Two Platforms ([email protected]);
(2) Michael Sapienza, Two Platforms ([email protected]);
(3) Steven Ripplinger, Two Platforms ([email protected]);
(4) Simon Gibbs, Two Platforms ([email protected]);
(5) Jaewon Lee, Two Platforms ([email protected]);
(6) Pranav Mistry, Two Platforms ([email protected]).
This paper is