

Table of Links
3 SUTRA Approach
4 Training Multilingual Tokenizers
5 Multilingual MMLU
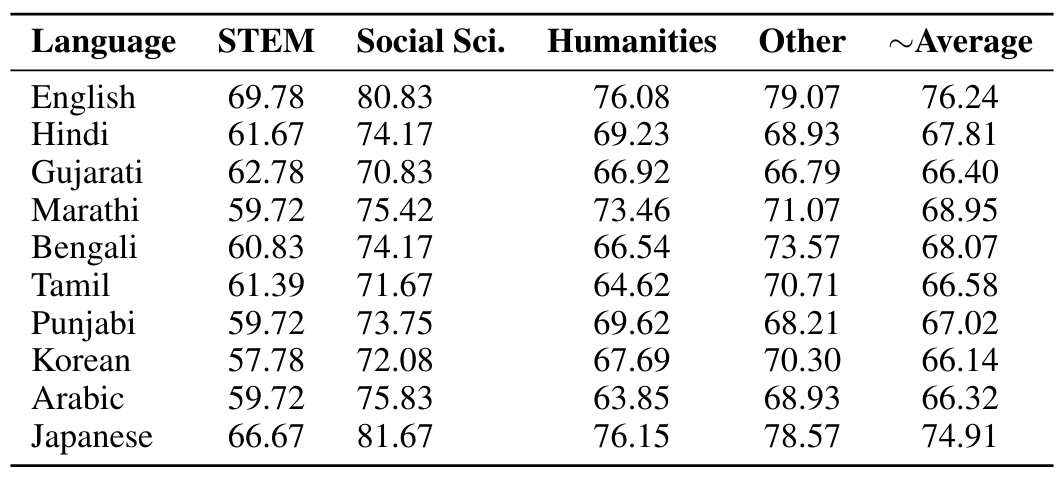
5.1 Massive Multitask Language Understanding
5.2 Extending MMLU to Multiple Languages and 5.3 Consistent Performance across Languages
5.4 Comparing with leading models for Multilingual Performance
6 Quantitative Evaluation for Real-Time Queries
7 Discussion and Conclusion, and References
6 Quantitative Evaluation for Real-Time Queries
SUTRA models are connected, up-to-date, and hallucination-free models that provide factual responses with a conversational tone. They are online LLMs that use, infer, and process real-time knowledge from the internet and leverage it to provide the most up-to-date information when forming responses. SUTRA-Online models can accurately respond to time-sensitive queries, extending its knowledge beyond a static training corpus. Online models can therefore accurately answer questions like "Who won the game last night” or “What’s the most popular movie right now?”.
We evaluated the SUTRA models using the Fresh Prompt framework [Vu et al., 2023], developed by Google for assessing online LLMs [Press et al., 2022], and discovered that SUTRA-Online models surpass the competing search
![Table 9: Performance Comparison of Language Models for handling fresh (realtime queries) with valid premise according to freshness LLM benchmark from Vu et al. [2023]](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-oj934ea.png)
engine-augmented models from Google, as well as OpenAI’s GPT-3.5 and Perplexity AI. The benchmark contains exhaustive questions covering various nuanced online scenarios covering never-changing, in which the answer almost never changes; slow-changing, in which the answer typically changes over the course of several years; fast-changing, in which the answer typically changes within a year or less. SUTRA performed well across majority of these scenarios, as shown in Table 9.
Authors:
(1) Abhijit Bendale, Two Platforms ([email protected]);
(2) Michael Sapienza, Two Platforms ([email protected]);
(3) Steven Ripplinger, Two Platforms ([email protected]);
(4) Simon Gibbs, Two Platforms ([email protected]);
(5) Jaewon Lee, Two Platforms ([email protected]);
(6) Pranav Mistry, Two Platforms ([email protected]).
This paper is